Технология OCR (оптическое распознавание символов) изменила правила игры в области оцифровки печатного или рукописного текста из физических документов и сделала его редактируемым и доступным для поиска. Удаление OCR из файла PDF по сути означает преобразование текста в PDF обратно в изображения или просто удаление распознанного текстового слоя. Существуют различные способы удаления OCR из файлов PDF.
В этой статье мы шаг за шагом проведем вас через процесс удаления OCR из PDF-файлов. Продолжайте читать и узнайте, как удалить OCR из PDF.
Причины, по которым вы можете захотеть удалить OCR из файлов PDF, включают:
Подробнее: [Решено] Как легко и эффективно удалить разрешения из PDF-файлов
WPS — это офисный пакет для MS Windows , Android , macOS, iOS , Linux и HarmonyOS. Он может помочь вам создавать и просматривать файлы на ходу, если он установлен на вашем гаджете. Вы также можете использовать специальные функции WPS, чтобы легко удалить OCR из ваших PDF-файлов. Вот как удалить текст OCR из PDF с помощью WPS Office.
Шаг 1. Убедитесь, что вы установили WPS на свое устройство, затем откройте PDF-файл с помощью WPS.
Шаг 2. Откройте вкладку «Инструменты» в верхнем меню после открытия PDF-файла.
Шаг 3. Выберите «OCR» на панели «Инструменты», и откроется окно с настройками OCR.
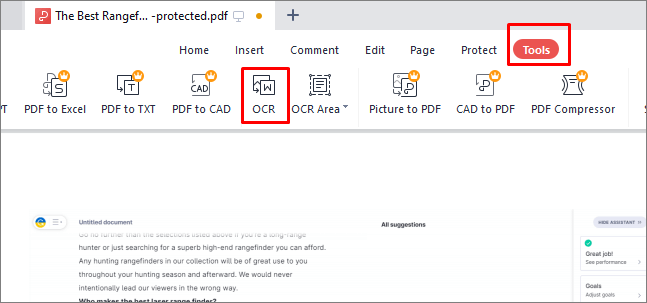
Шаг 4. Установите для языка OCR значение «Нет», чтобы удалить OCR из PDF-файла, в раскрывающемся меню языка OCR.
Шаг 5. Нажмите «ОК», чтобы сохранить настройки. Затем нажмите кнопку «Конвертировать», чтобы преобразовать PDF-файл без распознавания текста.
Шаг 6. Наконец, нажмите кнопку «Файл» в верхнем меню, затем выберите «Сохранить как» и соответствующим образом переименуйте новый PDF-файл.
Не пропустите: легкое удаление фона из PDF-документов [Практическое руководство]
Adobe Acrobat предлагает множество функций для создания и редактирования PDF-файлов. Одна из этих функций включает удаление OCR из файлов PDF. Вы можете использовать его как настольное приложение или онлайн через веб-браузер.
Adobe Acrobat позволяет отключать/удалять функцию оптического распознавания символов для PDF-файлов или отсканированных документов. OCR имеет тенденцию включаться по умолчанию. Таким образом, в большинстве случаев, когда вы открываете PDF-файл или отсканированный документ для редактирования, текущая страница преобразуется в редактируемый текст. К счастью, вы можете удалить или отключить/включить функцию автоматического распознавания текста, в зависимости от того, хотите ли вы преобразовать файл в редактируемый текст. Вот как удалить автоматическое распознавание текста из PDF-файлов с помощью Adobe Acrobat.
Шаг 1. Убедитесь, что на вашем компьютере установлен Adobe Acrobat. Запустите приложение, затем перейдите в «Инструменты» и нажмите «Редактировать PDF».
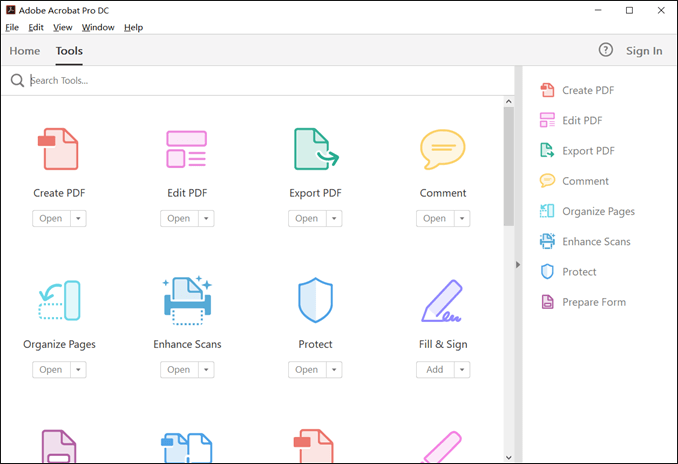
Шаг 2. Чтобы удалить или отключить распознавание текста, перейдите на правую панель и снимите флажок «Распознавать текст». Таким образом, Adobe не будет автоматически включать распознавание текста в вашем PDF/отсканированном документе.
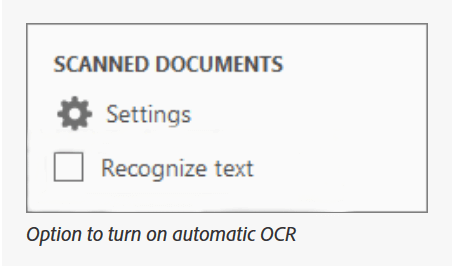
Примечание. Если выходные данные OCR получены из изображения с возможностью поиска или точного изображения с возможностью поиска, вы можете использовать Adobe Acrobat Pro для удаления OCR. Если вы используете Adobe Acrobat X, перейдите в «Инструменты» > «Защита» > «Скрытая информация». Нажмите кнопку «Удалить» на панели «Удалить скрытую информацию». Если вы видите галочку рядом с записью «Скрытый текст», это означает, что вывод OCR удален.
С другой стороны, если вы используете Adobe Acrobat 8, перейдите в «Документ», затем перейдите к «Проверить документ». Нажмите значок «Удалить все отмеченные элементы» в диалоговом окне «Проверить документ». Если флажок «Скрытый текст» отмечен галочкой, это означает, что вывод OCR удален.
Если у вас есть стопка старых печатных документов, рукописное письмо или отсканированное изображение с важной информацией, преобразование их в редактируемый текст может сэкономить вам время и усилия. PDFelement — это универсальное и удобное программное решение, которое поможет вам эффективно выполнить эту задачу. Хотя PDFelement не может напрямую удалить OCR из PDF, он может конвертировать отсканированные документы или текст с изображений в редактируемый текст.
Помимо преобразования отсканированных документов и текста, PDFelement может выполнять множество других функций редактирования PDF, таких как удаление верхних и нижних колонтитулов из PDF-файлов , удаление текста из PDF-файлов, удаление заполняемых полей из PDF-файлов или удаление водяных знаков из PDF-файлов и т. д. Этот конвертер документов настоятельно рекомендуется для его функция пакетной обработки. Он может обрабатывать несколько PDF-файлов одновременно без ущерба для качества файла.
Удивительные возможности PDFelement включают в себя:
Вот как использовать PDFelement для преобразования отсканированных документов или текста из изображений в редактируемый текст.
01 Загрузите, установите и запустите PDFelement на своем устройстве. Нажмите «Открыть PDF», чтобы загрузить PDF для редактирования.
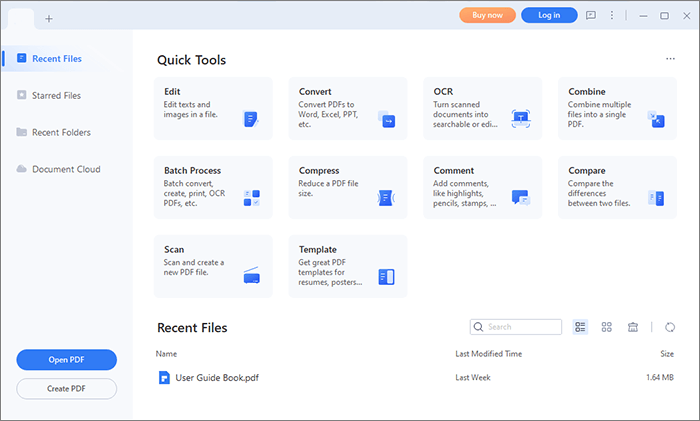
02 Нажмите кнопку «Инструменты» и выберите «OCR».
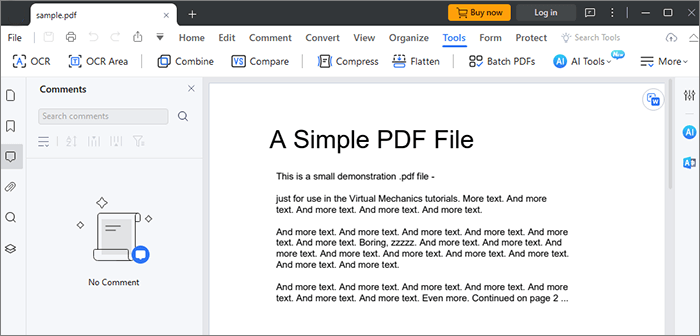
03 На этом этапе появится всплывающее окно. Выберите «Сканировать в редактируемый текст», затем выберите нужные номера страниц и язык и нажмите «Применить».
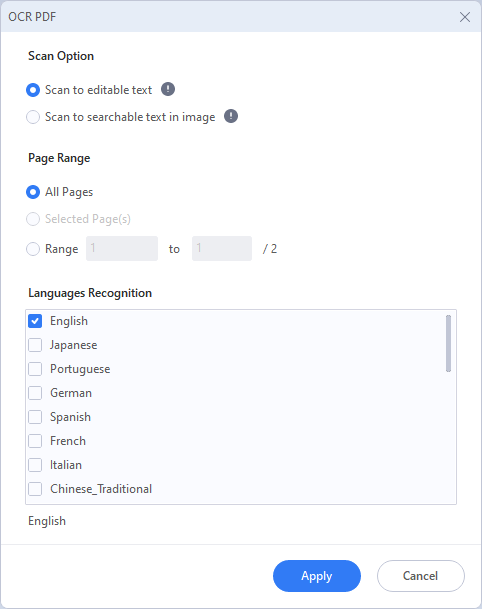
04 После завершения процесса программа автоматически откроет вновь созданный редактируемый PDF-файл. Когда он откроется, вы можете нажать кнопку «Редактировать», чтобы внести изменения в текст PDF.
Вопрос 1: Каковы преимущества использования средства для удаления OCR?
Использование мощного средства для удаления OCR имеет ряд преимуществ, в том числе:
Вопрос 2. Как удалить слои OCR из PDF-файла онлайн?
Существует несколько ручных методов удаления слоев OCR из PDF-файлов. Одним из распространенных способов является печать PDF-файла . Функция печати по умолчанию в Windows предположительно удаляет текстовый слой. Другой способ удалить слой OCR из PDF — это утилита командной строки, то есть написание сценария.
Вопрос 3. Как узнать, было ли к PDF-файлу применено распознавание текста?
Откройте PDF-файл и найдите, можно ли искать в файле слова или можно ли выделить любой текст. Если вы не можете выделить текст или выполнить поиск в PDF-файле , возможно, это отсканированное изображение. С другой стороны, если вы можете искать или выделять текст в PDF-файле, велика вероятность, что было применено OCR.
Удаление OCR из PDF-файлов — это простой процесс, который дает ряд преимуществ, включая повышенную безопасность документов, улучшенное качество файлов и повышенную совместимость на различных устройствах и платформах. Для этого вам понадобится специальный и удобный инструмент. Методы и решения, которые мы здесь обсуждали, предоставляют вам возможность бесплатно удалить OCR из PDF-файлов, а для тех, кто ищет более продвинутые функции, также доступны альтернативы премиум-класса.
Однако, если вы хотите отредактировать или преобразовать отсканированные PDF-файлы, PDFelement одержит победу. Это мощное программное обеспечение для редактирования PDF-файлов с множеством возможностей и функций.
Похожие статьи:
Лучший бесплатный конвертер PDF в Word в автономном режиме: простое преобразование PDF в Word
[Обзор 9 инструментов] Самый популярный конвертер PDF в Word онлайн/офлайн
Как отсканировать изображение в PDF как профессионал? Ваше полное руководство




 Бесплатная загрузка для ПК
Бесплатная загрузка для ПК Бесплатная загрузка для Mac
Бесплатная загрузка для Mac

