PDF-файлы широко распространены в обширной сфере цифровых документов благодаря своей универсальной совместимости и способности сохранять целостность документа. Тем не менее, извлечение текста из отсканированных PDF-файлов или PDF-файлов на основе изображений может оказаться утомительным занятием. К счастью, при наличии правильного программного обеспечения и процедур вы можете быстро конвертировать изображения PDF в текст без потери качества.
Эти программы позволяют получить доступ к тексту, скрытому на картинках. Это позволяет редактировать, искать и повторно использовать изображение PDF в других контекстах. В этой статье подробно описано, как извлечь текст из изображения PDF, а также другие полезные советы.
Благодаря своей доступности и простоте использования многие автономные приложения превосходно конвертируют изображения PDF в текст. В ситуациях, когда вам необходимо защитить конфиденциальность своей работы, иметь полный контроль над процессом преобразования или у вас нет доступа к Интернету, офлайн-инструменты пригодятся. Вот несколько отличных офлайн-методов для извлечения текста из PDF-изображения:
PDFelement — это надежный редактор PDF, который импортирует отсканированные документы и позволяет изменять текст в изображении PDF, экспортируя его в файл Word или TXT. Это облегчает редактирование так же, как и в обычном текстовом документе.
Помимо преобразования PDF-файлов в изображения и из них, PDFelement также поддерживает преобразование PDF-файлов в различные типы файлов, такие как DOCX , PPTX, XLS, HTML, RTF и TXT, и из них. Простота использования является одной из его определяющих характеристик. PDFelement является кроссплатформенным и поддерживает Mac OS X, Windows , iOS и Android .
Вот некоторые ключевые особенности PDFelement, которые делают его одним из лучших редакторов PDF:
Итак, как конвертировать PDF-изображение в текст с помощью PDFelement?
01 Загрузите и запустите PDFelement. Перетащите файл изображения в программу, чтобы открыть его.
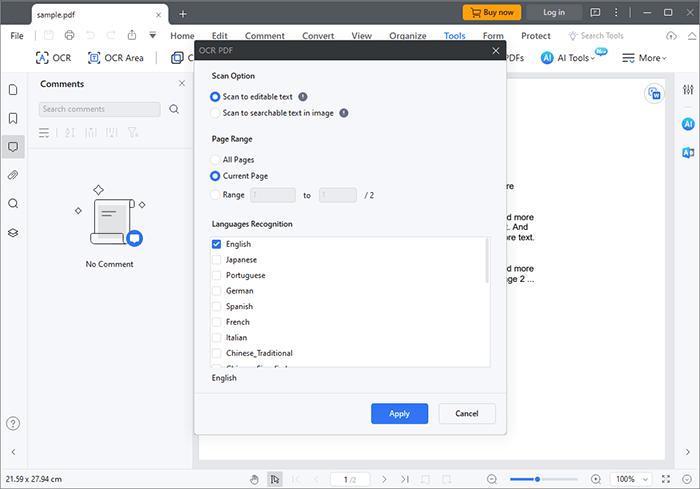
02 Чтобы активировать OCR, нажмите «Инструменты» и нажмите кнопку «OCR»; выберите опцию «Сканировать в редактируемый текст». Выберите страницу и нужный язык, затем нажмите «Применить», чтобы перевести текст и заголовки фотографии на выбранный вами язык.
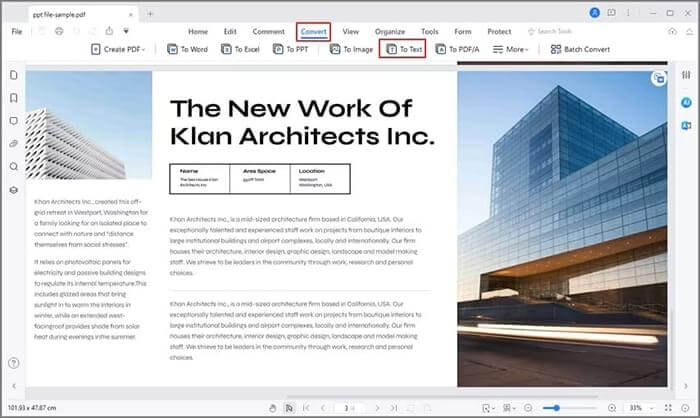
03 Нажмите «Преобразовать» > «В текст» на появившейся домашней странице. Выберите «TXT» из раскрывающегося списка, назовите и сохраните файл в выбранной папке и нажмите «ОК».
Adobe Acrobat для Windows и Mac избавляет от необходимости перепечатывать, переформатировать или повторно сканировать PDF-файлы для получения текстовых документов, которые можно редактировать и осуществлять поиск. Вы можете конвертировать отсканированные PDF-файлы в текстовые файлы, используя надежную встроенную функцию распознавания текста, сохраняя при этом исходные шрифты и структуру.
Выполните следующие простые шаги, чтобы извлечь текст из изображений PDF с помощью Adobe Acrobat:
Шаг 1. Запустите Adobe Acrobat после его загрузки, затем откройте отсканированный документ, который хотите распознать, и выберите «Инструменты». Начните с выбора «Распознать текст», а затем «В этом файле».
Шаг 2. Доступны элементы управления для настройки оптического распознавания текста. Чтобы продолжить распознавание текста, выберите «ОК», если документ, который вы хотите перевести, написан на языке, установленном в системе по умолчанию. Нажмите «Редактировать» и выберите «Основной язык распознавания» > «Стиль вывода PDF» > «Понижение разрешения до».
Шаг 3. Направьте изображение PDF вправо и выберите «Копировать с форматированием». Acrobat сохранит распознанный текст в исходном файле, если вы распознаете PDF-файл. Однако если вы распознаете изображение, оно сохранится вместе с текстом в новом PDF-файле.
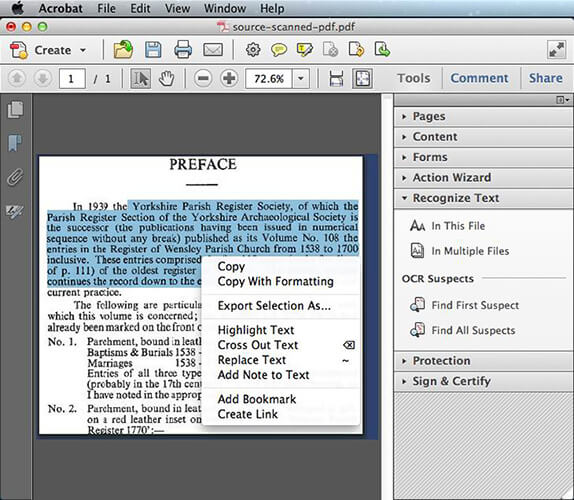
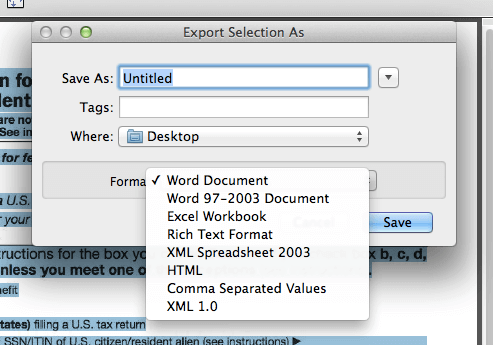
Шаг 4. Вы попадете на вкладку «Экспортировать выбранное как». Чтобы экспортировать файлы OCR, выберите «Сохранить как» и выберите «Документ Word» в качестве типа файла. Выберите место для нового файла и сохраните его.
Soda PDF — это набор из более чем 50 PDF-приложений для ПК и мобильных устройств, упрощающих преобразование, защиту, создание и редактирование PDF-файлов . Встроенная технология OCR позволяет плавно конвертировать PDF-файлы с изображениями в редактируемый текст.
Узнайте, как копировать текст из изображений PDF с помощью Soda PDF:
Шаг 1. Загрузите PDF-файл Soda и запустите его. Выберите «Дополнительно» в модуле «Создать и конвертировать», затем выберите «PDF в TXT».
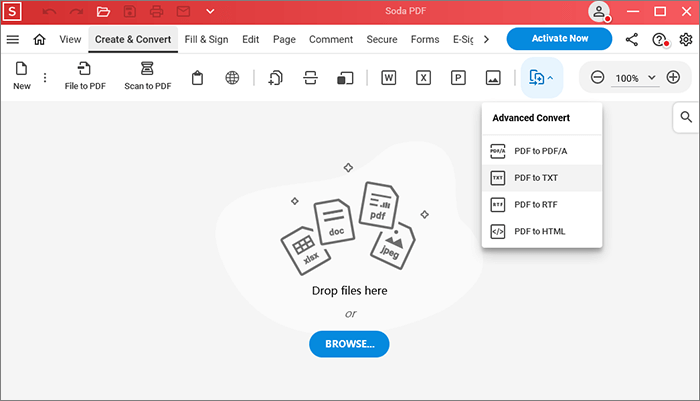
Шаг 2. Определите, какие страницы нуждаются в конверсии. Чтобы получить доступ к дополнительным настройкам, выберите три точки.
Шаг 3. Щелкните значок папки, чтобы изменить место сохранения по умолчанию. Используйте OCR, чтобы сделать отсканированный файл доступным для редактирования. Затем отметьте «Открыть документ TXT после конвертации» и нажмите «ЭКСПОРТ».
Шаг 4. Как только конвертация вашего файла будет завершена, вы получите это уведомление.
Может понравиться: Обзор программного обеспечения для оптического распознавания символов PDF в Word: раскрытие точности и эффективности
Копирование текста в формате PDF-изображений онлайн — это простое и эффективное решение. Вы можете конвертировать фотографии PDF в текст без установки какого-либо дополнительного программного обеспечения благодаря онлайн-приложениям, таким как iLovePDF, PDF2Go, Online OCR и т. д. Вот несколько полезных методов онлайн-преобразования изображений PDF в текст:
Одной из многих впечатляющих функций PDF2Go является функция оптического распознавания символов, которая позволяет быстро и легко конвертировать PDF-изображения в текст. Благодаря функциям оптического распознавания символов PDF2Go вы можете легко извлечь ключевые детали и открыть документы в формате, который можно редактировать.
Вот три простых шага по использованию PDF2Go для преобразования изображений PDF в текст.
Шаг 1. На сайте PDF2Go перетащите сюда файлы или нажмите «Выбрать файл».
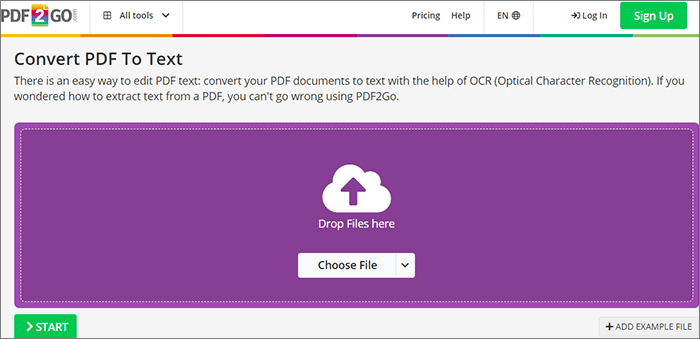
Шаг 2. Конвертируйте с помощью OCR и нажмите кнопку «СТАРТ».
Шаг 3. Загрузите конвертированный файл.
С помощью Online OCR вы можете легко конвертировать отсканированные PDF-файлы в редактируемый текст. Кроме того, любой тип файла изображения (JPG, BMP или PNG) можно преобразовать в текстовый формат вывода с сохранением форматирования исходного файла. Онлайн-распознавание текста совместимо с Windows , Mac OS и Linux.
Следуйте приведенной ниже простой процедуре, чтобы преобразовать изображения PDF в текст с помощью Online OCR:
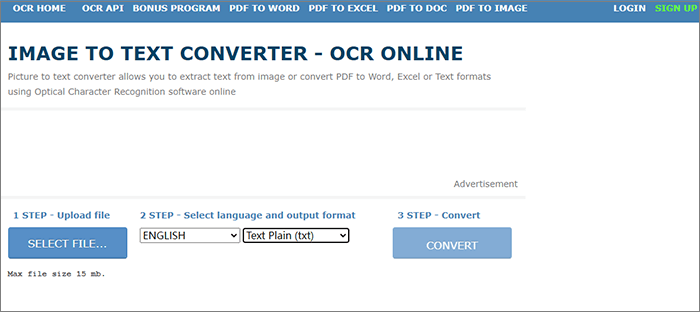
Шаг 1. На странице онлайн-распознавания текста нажмите «ВЫБРАТЬ ФАЙЛ», выберите язык «АНГЛИЙСКИЙ» и формат вывода «Обычный текст». Затем нажмите кнопку «ПРЕОБРАЗОВАТЬ».
Шаг 2. Загрузите выходной файл.
См. также: [Комплексное руководство] Как сохранить PDF как документ Word
OCR2EDIT — это передовая программа, которая позволяет пользователям читать текст из отсканированных PDF-файлов. Удобный интерфейс дает возможность быстро и точно извлекать текст из отсканированных фотографий.
Выполните следующие простые шаги, чтобы преобразовать отсканированные изображения PDF в текст с помощью OCR2EDIT:
Шаг 1. Откройте веб-страницу OCR2EDIT и нажмите «Выбрать файл» или перетащите файлы сюда.
Шаг 2. В настройках OCR настройте в соответствии с вашими потребностями. Затем нажмите «Начать».
Шаг 3. Загрузите конвертированный файл.
iLovePDF, известная онлайн-платформа для задач, связанных с PDF. Он предоставляет простой метод преобразования PDF-файлов, созданных из изображений, в редактируемые текстовые файлы. Используя программу OCR iLovePDF, вы можете получать доступ и работать с текстом в PDF-файлах, созданным из отсканированных изображений и графического контента. Выполните эти 3 ключевых шага, чтобы узнать, как конвертировать отсканированные изображения PDF в текст с помощью iLovePDF.
Шаг 1. На веб-сайте iLovePDF нажмите «Выбрать PDF-файл» или перетащите PDF сюда.
Шаг 2. Нажмите «OCR PDF».
Шаг 3. Загрузите PDF-файл, который вы можете выбрать и выполнить поиск по своему усмотрению.
Google Docs — это бесплатный онлайн-сервис, позволяющий пользователям открывать, читать, редактировать и экспортировать PDF , Word, изображения и другие форматы. Он также может выполнять распознавание текста на отсканированных PDF-файлах и изображениях. Однако если вы используете OCR Документов Google, вам придется исправить форматирование вручную. Следуйте приведенной ниже простой процедуре, чтобы извлечь изображения и текст из PDF:
Шаг 1. Загрузите файлы на свой Google Диск на вкладке «Мой диск».
Шаг 2. Щелкните правой кнопкой мыши изображение PDF. Выберите «Открыть с помощью» > «Документы Google».
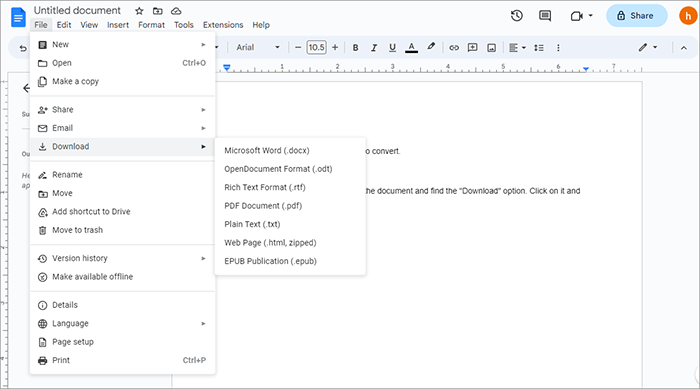
Шаг 3. Содержимое файла теперь можно редактировать в Документах Google. Нажмите «Файл» > «Загрузить» > «Обычный текст (.txt)».
Знание того, как конвертировать изображения PDF в текст, полезно для того, чтобы сделать документы более доступными и удобными для использования. Мы предлагаем использовать PDFelement среди различных альтернатив, доступных для этой цели. Его инновационная и простая функция распознавания текста выделяет его из толпы. Загрузите его сейчас для точного преобразования текста PDF из изображений.
Похожие статьи:
Как легко встроить PDF-файл в Word? [Советы и рекомендации]
Как вставить PDF в документ Google: быстрые и простые шаги
Как удалить текст из PDF [Полное руководство]
Как конвертировать PDF в PNG с высоким качеством? 8 советов и рекомендаций экспертов




 Бесплатная загрузка для ПК
Бесплатная загрузка для ПК Бесплатная загрузка для Mac
Бесплатная загрузка для Mac

